Este capítulo es una corta revisión de las técnicas de programación. Utilizamos un sencillo ejemplo para ilustrar sus propiedades particulares y para exponer sus ideas principales y sus problemáticas.
En términos generales, podemos distinguir la siguiente curva de aprendizaje de alguien que aprende a programar :
Este capítulo está organizado como sigue. Las secciones 2.1 a 2.3 brevemente describen las primeras tres técnicas de programación. Subsecuentemente, presentamos un ejemplo sencillo de como la programación modular puede usarse para implementar un módulo de lista ligada sencilla (sección 2.4). Por medio de esto, denotamos unos cuantos problemas con este tipo de técnica en la sección 2.5. Finalmente, la sección 2.6 describe la cuarta técnica de programación.
 |
Como todos deberían saber, estas técnicas de programación ofrecen tremendas desventajas una vez que el programa se hace suficientemente grande. Por ejemplo, si la misma secuencia de instrucciones se necesita en diferentes situaciones dentro del programa, la secuencia debe ser repetida. Esto ha conducido a la idea de extraer estas secuencias, darles un nombre y ofrecer una técnica para llamarlas y regresar desde estos procedimientos.
 |
Al introducir parámetros así como procedimientos de procedimientos ( subprocedimientos) los programas ahora pueden ser escritos en forma más estructurada y libres de errores. Por ejemplo, si un procedimiento ya es correcto, cada vez que es usado produce resultados correctos. Por consecuencia, en caso de errores, se puede reducir la búsqueda a aquellos lugares que todavía no han sido revisados.
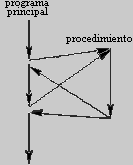
De este modo, un programa puede ser visto como una secuencia de llamadas a procedimientos
![[*]](foot.gif) . El programa principal es responsable de pasar los datos a las llamadas individuales, los datos son procesados por los procedimientos y, una vez que el programa ha terminado, los datos resultantes son presentados.
Así, el flujo de datos puede ser ilustrado como una gráfica jerárquica, un
árbol, como se muestra en la
Fig. 2.3 para un programa sin subprocedimientos.
. El programa principal es responsable de pasar los datos a las llamadas individuales, los datos son procesados por los procedimientos y, una vez que el programa ha terminado, los datos resultantes son presentados.
Así, el flujo de datos puede ser ilustrado como una gráfica jerárquica, un
árbol, como se muestra en la
Fig. 2.3 para un programa sin subprocedimientos.
 |
Para resumir : tenemos ahora un programa único que se divide en pequeñas piezas llamadas procedimientos. Para posibilitar el uso de procedimientos generales o grupos de procedimientos también en otros programas, aquéllos deben estar disponibles en forma separada. Por esa razón, la programación modular permite el agrupamiento de procedimientos dentro de módulos.
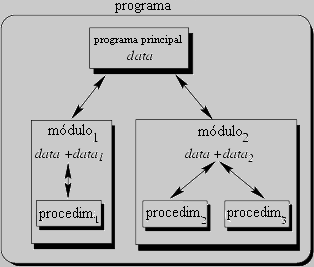 |
Cada módulo puede contener sus propios datos. Esto permite que cada módulo maneje un estado interno que es modificado por las llamadas a procedimientos de ese módulo. Sin embargo, solamente hay un estado por módulo y cada módulo existe cuando más una vez en todo el programa.
Las listas ligadas sencillas proveen solamente métodos para añadir un elemento nuevo al final y para suprimir el elemento del frente. Las estructuras de datos complejas pueden usar estructuras ya existentes. Por ejemplo una cola puede ser estructurada como una lista ligada sencilla. Sin embargo, las colas proveen métodos de acceso para poner un elemento de datos al final y para obtener el primer elemento de datos. (comportamientofirst-in first-out (FIFO), es decir, "primero-en-entrar-primero-en-salir").
Presentaremos ahora un ejemplo que usamos para presentar algunos conceptos de diseño. Desde el momento que este ejemplo se usa solamente para ilustrar estos conceptos y problemas, no es un ejemplo completo ni es el óptimo. Refiérase al capítulo 10 para una discusión completa de orientación a objetos acerca del diseño de estructuras de datos.
Suponiendo que se quiera programar una lista en un lenguaje de programación modular tal como C o Modula-2. Como tú crees que las listas pertenencen a una estructura de datos común, decides implementarla en un módulo separado. Típicamente, esto requiere que escribas dos archivos : la definición de la interface y el archivo de implementación. Dentro de este capítulo usaremos un pseudo código muy sencillo que se debería entender de inmediato. Asumamos que los comentarios están delimitados por ``/* ... */''. Nuestra definición de interface pudiera ser similar a la de abajo :
/*
* Definición de interface para un módulo que implementa
* una lista ligada sencilla para almacenar datos de cualquier tipo.
*/
MODULE Singly-Linked-List-1
BOOL list_initialize();
BOOL list_append(ANY data);
BOOL list_delete();
list_end();
ANY list_getFirst();
ANY list_getNext();
BOOL list_isEmpty();
END Singly-Linked-List-1
Las definiciones de interface solamente describen lo que está disponible pero no el cómo ésto se hace disponible. Se esconde la información de la implementación en el archivo de implementación. Este es un principio fundamental en ingeniería de software, de modo que repitámoslo : Se esconde la información de la implementación real (ocultamiento de la información). Esto te permite cambiar la implementación. Por ejemplo, para usar un algoritmo más rápido pero de más consumo de memoria para almacenar elementos sin la necesidad de cambiar otros módulos de tu programa : Las llamadas a los procedimientos provistos permanecen iguales.
La idea de esta interface es la siguiente : Antes de usar la lista, uno debe llamar a
list_initialize() para inicializar las variables locales a dicho módulo. Los siguientes dos procedimientos implementan los métodos de acceso mencionados
append
y delete. El procedimiento append necesita una discusión más detallada.
La función list_append() lleva un argumento data de tipo arbitrario.
Esto es necesario desde el momento que deseas usar tu lista en varios ambientes diferentes, por lo tanto, el tipo de los elementos de datos a ser almacenados en la lista no es conocido de antemano.
Por consecuencia, debes usar un tipo de datos especial ANY el cuál permite asignarle datos de cualquier tipo.
El tercer procedimiento list_end() necesita ser llamado cuando el programa termina con el fin de permitirle al módulo limpiar sus variables usadas internamente. Por ejemplo, tu pudieras desear liberar la memoria asignada.
Con los siguientes dos procedimientos list_getFirst() y list_getNext() se ofrece un mecanismo simple para desplazarse a través de la lista. El desplazamiento puede hacerse usando el siguiente bucle :
ANY data;
data <- list_getFirst();
WHILE data IS VALID DO
doSomething(data);
data <- list_getNext();
END
Se tiene ahora un módulo de lista que permite usar la lista con cualquier tipo de elemento de datos. Pero, ¿Qué si necesitas más de una lista en uno de tus programas ?
/*
* Un módulo de lista para más de una lista.
*/
MODULE Singly-Linked-List-2
DECLARE TYPE list_handle_t;
list_handle_t list_create();
list_destroy(list_handle_t this);
BOOL list_append(list_handle_t this, ANY data);
ANY list_getFirst(list_handle_t this);
ANY list_getNext(list_handle_t this);
BOOL list_isEmpty(list_handle_t this);
END Singly-Linked-List-2;
Usas DECLARE TYPE para introducir un nuevo tipo list_handle_t el cuál representa tu manejador de lista. No especificamos como este manejador está realmente representado o aún implementado. También escondes los detalles de la implementación de este tipo de datos en el archivo de implementación. Nótese la diferencia con la versión anterior en la cuál solamente escondes funciones o procedimientos, respectivamente. Ahora, también escondes la información de un tipo de datos definido por el usuario llamado list_handle_t.
Usas list_create() para obtener un manejador a una nueva (y por lo mismo vacía) lista. Cada uno de los otros procedimientos contiene el parámetro especial this el cuál solamente identifica la lista en cuestión. Todos los procedimientos operan ahora sobre este manejador en lugar de operar sobre una lista global modular.
Podrías decir ahora, que puedes crear objetos lista. Cada uno de tales objetos puede ser unívocamente identificado por su manejador y solamente se les pueden aplicar aquellos métodos que son definidos para operar sobre este manejador.
En el ejemplo, cada vez que quieres usar una lista, tienes que declarar explícitamente un manejador y hacer una llamada a list_create() para obtener un manejador de lista válido. Después del uso de la lista, debes llamar explícitamente a list_destroy() con el manejador de la lista que quieres que se destruya. Si quieres usar una lista dentro de un procedimiento, digamos, foo() , usas el siguiente esqueleto de código :
PROCEDURE foo() BEGIN
list_handle_t myList;
myList <- list_create();
/* Do something with myList */
...
list_destroy(myList);
END
Comparemos la lista con otros tipos de datos, por ejemplo un entero. Los enteros se declaran dentro de un ámbito particular (por ejemplo, dentro de un procedimiento). Una vez que los has definido, puedes usarlos. Una vez que abandonas el ámbito (el procedimiento donde fue definido el entero, por ejemplo) el entero se pierde. Se crea y se destruye automáticamente. Algunos compiladores también inicializan los enteros recién creados con un valor, típicamente 0 (cero).
¿Cuál es la diferencia con lo "objetos" tipo lista ? La vida de una lista también está definida por su ámbito, por lo tanto, debe crearse una vez que se entra al ámbito y destruirse una vez que se abandona. En el momento de su creación, una lista debería inicializarse vacía. Por consiguiente, nos gustaría poder definir un lista en forma similar a la definición de un entero. Un esqueleto de código para ésto se vería del siguiente modo :
PROCEDURE foo() BEGIN
list_handle_t myList; /* La lista es creada e inicializada */
/* Hacer algo con myList */
...
END /* myList es destruída */
La ventaja estriba en que ahora el compilador se toma el cuidado de llamar en forma apropiada los procedimientos de inicialización y de finalización. Por ejemplo, esto asegura que la lista sea correctamente eliminada, regresando los recursos al programa.
El desacoplamiento de datos y operaciones conduce usualmente a una estructura basada en las operaciones en lugar de en los datos : Los Módulos agrupan las operaciones comunes (tales como aquéllas operaciones list_...()) en forma conjunta. Tú entonces usas estas operaciones proveyéndoles explícitamente los datos sobre los cuáles deben operar. La estructura de módulo resultante está por lo tanto orientada a las operaciones más que sobre los datos. Se podría decir que las operaciones definidas especifican los datos que serán usados.
En orientación a objetos, la estructura se organiza por los datos. Tú escoges las representaciones de datos que mejor se ajusten a tus requerimientos. Por consecuencia, tus programas se estructuran por los datos más que por las operaciones. Así, esto es exactamente del otro modo : Los datos especifican las operaciones válidas. Ahora, los módulos agrupan representaciones de datos en forma conjunta.
PROCEDURE foo() BEGIN
SomeDataType data1;
SomeOtherType data2;
list_handle_t myList;
myList <- list_create();
list_append(myList, data1);
list_append(myList, data2); /* Oops */
...
list_destroy(myList);
END
Es tu responsablilidad asegurarte que tu lista sea usada consistentemente. Una posible solución es añadir información adicional acerca del tipo de datos a cada elemento de la lista. Sin embargo, esto implica más overhead y no te salva de saber qué es lo que estás haciendo.
Lo que quisiéramos tener es un mecanismo que nos permita especificar sobre que tipos de datos debería ser definida la lista. La función total de la lista es siempre la misma, sin importar si almacenamos manzanas, números, autos o aún listas. Por lo tanto, sería bueno declarar una nueva lista con algo como ésto :
list_handle_t<Apple> list1; /* una lista de manzanas */
list_handle_t<Car> list2; /* una lista de carros */
Las correspondientes rutinas de la lista deberían entonces regresar automáticamente los tipos correctos de datos. El compilador debería poder checar la consistencia de los tipos.
El ejemplo de la lista implica operaciones para desplazarse a través de la lista. Típicamente, se usa un cursor para ese propósito, el cuál apunta al elemento actual. Esto implica una estrategia de recorrido que define el orden en el que los elementos de la estructura de datos serán visitados.
Para una estructura de datos simple como la lista sencilla ligada, uno puede pensar en únicamente una estrategia de recorrido. Empezando con el elemento más hacia la izquierda, uno visita sucesivamente los vecinos de la derecha hasta que se alcanza el último elemento. Sin embargo, estructuras de datos más complejas tales como los árboles, pueden ser recorridos usando diferentes estrategias. Peor aún, algunas veces las estrategias de recorrido dependen del contexto particular en el que se usa la estructura de datos. Consecuentemente, tiene sentido el separar la representación o forma de la estructura de datos de su estrategia de recorrido. Investigaremos ésto con más detalle en el capítulo 10.
Lo que hemos mostrado con la estrategia de recorrido se aplica a otras estrategias por igual. Por ejemplo, la inserción de un elemento puede ser hecha de modo tal que se realice un ordenamiento de elementos o se deje de hacer esto último.
 |
Considera el ejemplo de listas múltiples nuevamente. El problema aquí con la programación modular es, que tú debes crear y destruir en forma explícita tus manejadores de lista. Entonces tú usas los procedimientos del módulo para modificar cada uno de tus manejadores.
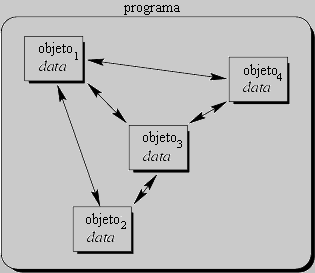
En contraste con eso, en la programación orientada a objetos deberíamos tener tantos objetos-lista como sea necesario. En lugar de llamar un procedimiento al que le debemos proveer el manejador de lista correcto, mandaríamos un mensaje directamente al objeto-lista en cuestión. En términos generales, cada objeto implementa su propio módulo, permitiendo por ejemplo que coexistan muchas listas.
Cada objeto es responsable de inicializarse y destruirse en forma correcta. Por consiguiente, ya no existe la necesidad de llamar explícitamente al procedimiento de creación o de terminación.
Te podrías preguntar : ¿Y qué? ¿No es ésta solamente una manera más elegante de técnica de programación modular ? Tendrías razón, si ésto fuera todo acerca de la orientación a objetos. Afortunadamente no lo es. Empezando en los siguientes capítulos, se introducen características adicionales de orientación a objetos que hacen de la programación orientada a objetos una técnica novedosa de programación.
